通过 ComfuUI 学习
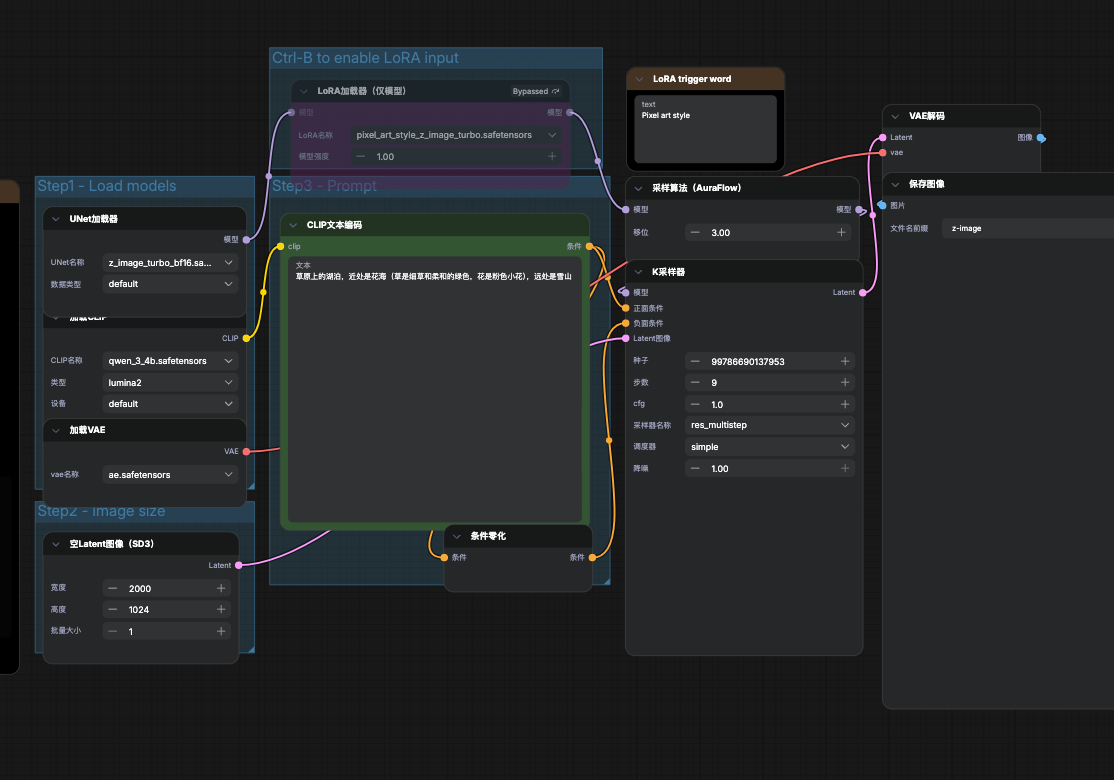
以上是一个 ComfyUI 的工作流
细心的人注意到了节点上的各种加载器,comfy 默认支持以下加载器
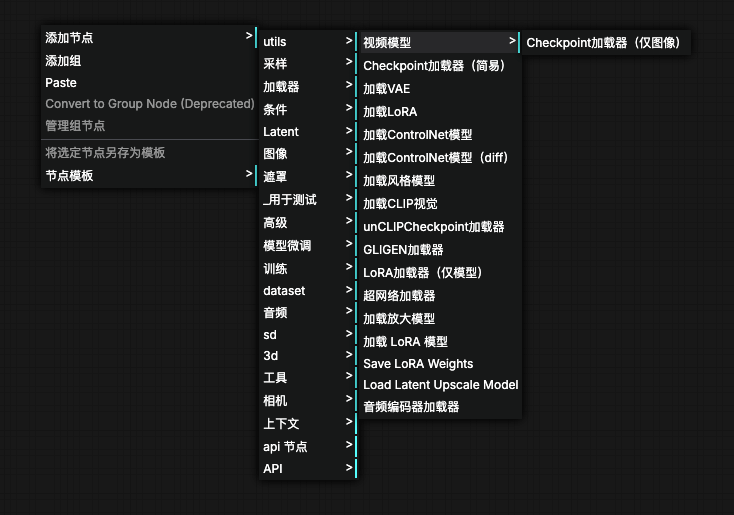
其中的 VAE、LoRA、ControlNet 等是什么呢,不是研究模型而仅是做些应用的我非常好奇,接下来一起学习下吧
ComfyUI 是什么
ComfyUI 是目前 AI 绘画领域(特别是 Stable Diffusion 和 Flux 生态)中最强大、最硬核,也是目前最主流的图形用户界面(GUI)。
如果说以前大家常用的 Stable Diffusion WebUI (俗称“秋叶包”或 WebUI) 是一辆自动挡汽车(面板上都是现成的按钮和滑块,挂上 D 挡就能开),那么 ComfyUI 就是一辆手动挡的 F1 赛车,或者说它更像是一个乐高积木拼装台。
在 ComfyUI 中,没有固定的“生成”面板,一切都是由**节点(Nodes)和连线(Wires)**组成的。
1. ComfyUI 的核心工作原理:节点式工作流
当你第一次打开 ComfyUI 时,你看到的不是按钮,而是一堆带插孔的方块,中间连着像面条一样的线。这就是它的核心:基于节点的工作流(Node-based Workflow)。
图像生成的过程被拆解成了最底层的步骤。一个最基础的画图流程是由以下几个节点连在一起的:
- Load Checkpoint(加载底模):把大模型(比如 Flux.1)装载进内存。
- CLIP Text Encode(文本编码):这是输入提示词的地方。你写下“一只猫”,CLIP 负责把文字翻译成 AI 能懂的数学向量。
- Empty Latent Image(空潜空间图像):给 AI 提供一张指定尺寸(比如 1024x1024)的“隐形画布”。
- KSampler(采样器):核心大脑。它接收模型、提示词和空画布,开始进行“去噪”(也就是作画)的过程。
- VAE Decode(VAE 解码):采样器画完后,画面还是潜空间里的数学代码,必须通过 VAE 翻译成我们肉眼能看的 RGB 像素图像。
- Save Image(保存图像):最后输出图片。
你必须把上一个节点的“输出端口”用线连到下一个节点的“输入端口”,数据才会像流水一样跑完整个管线。
2. 为什么现在的大神和专业开发者都在用 ComfyUI?
既然连线这么麻烦,为什么大家还要放弃简单的 WebUI 转投 ComfyUI?因为它有着无可比拟的优势:
- 极致的性能与显存管理(拯救低配显卡): ComfyUI 是在底层运行的。它非常聪明,如果你只改了提示词,它就不会重新加载模型;它会在显存不够时自动把数据转移到内存里。对于像 Flux 或 SDXL 这样几十 GB 的“性能怪兽”,很多显卡在 WebUI 里会直接崩溃,但在 ComfyUI 里却能流畅运行。
- 无限的灵活性(搭建专属流水线):
在 WebUI 里,你想先放大图片,再进行局部重绘,可能需要各种繁琐的切换。在 ComfyUI 里,你可以把节点无限连下去。比如:
生成图片 -> 传给人脸修复节点 -> 传给调色节点 -> 传给 4K 放大节点。按一次执行,电脑会自动跑完这条复杂的流水线。 - “杀手级”功能:图片即工作流(完美复现): 这是 ComfyUI 最迷人的特性。由于它是节点生成的,它会把你用了什么模型、什么参数、怎么连线的完整代码,偷偷隐藏在最后生成的那张 PNG 图片的属性里。 当你看到别人发了一张绝美的 ComfyUI 图片,你只需要把这张图片拖拽进你的 ComfyUI 网页里,砰!一秒钟,大神复杂的连线工作流就会原封不动地在你的屏幕上重现。
3. ComfyUI 的缺点
- 学习曲线极其陡峭: 刚打开它时,看着满屏幕的连线,很像黑客帝国的控制台,对非技术人员(尤其是没有用过 Nuke、Blender、Houdini 等节点软件的设计师)极度不友好。
- 连线地狱(Spaghetti): 当工作流变得复杂(比如加了 3 个 ControlNet、2 个 LoRA、外加高清修复)时,屏幕上的线会乱得像一团乱麻,稍不注意连错一根线,整个流程就会报错停工。
加载器加载了什么
ComfyUI 中的加载器(Loaders)负责将不同格式的 AI 模型文件加载到显存中,供后续的节点(如 KSampler)使用。这些文件是 AI 绘画的核心资产,它们的格式和加载方式直接决定了生成效果和性能。
UNet
UNet 是一个深度学习模型,用于图像处理和计算机视觉任务。它由多个卷积层和池化层组成,用于处理输入图像并生成输出图像。UNet 的核心是 U 形结构,它将输入图像分为多个区域,每个区域都通过卷积层进行处理,最后将处理后的区域连接起来,生成输出图像。
VAE
VAE(Variational Autoencoder)是一种无监督学习模型,用于对输入数据进行编码和解码。VAE 通过学习数据的分布,将输入数据映射到一个高维空间,并生成新的数据。VAE 的主要优点是它可以对数据进行压缩,并生成相似的数据。VAE 的主要缺点是它需要大量的训练数据才能进行训练,并且生成的数据可能会有噪声。
LoRA
LoRA(Low-Rank Adaptation)是一种用于模型微调的技巧,它可以提高模型的性能。LoRA 通过将模型的权重进行分解,将权重的某些部分进行缩放,并添加一个额外的权重矩阵,从而实现权重的微调。LoRA 的主要优点是它可以提高模型的性能,并且可以在训练过程中进行微调。LoRA 的主要缺点是它需要额外的权重矩阵,并且训练速度可能会变慢。
LoRA 与 UNet 的关系
如果用一句话来概括,LoRA 就是专门针对 UNet 进行“脑部微创手术”的临时外挂芯片。
我们在前面提到过,UNet 是底模的核心大脑,负责实际的去噪作画;而 LoRA 是特定画风或人物的补丁包。
那么,这个“补丁”究竟是打在哪里的?答案就是:绝大多数的 LoRA,都是直接“外挂”在 UNet 内部的神经网络层上的。
为了让你理解它们之间极其精妙的技术关系,我们需要稍微揭开一点底层的面纱:
1. 为什么我们需要 LoRA?(全量微调的痛点)
如果你想让 AI 记住“刘亦菲”的脸。最暴力的做法是:把整套几 GB 的底模(包含了庞大的 UNet)放进显卡里重新训练,强行改变 UNet 里那几十亿个神经元(权重矩阵)。 这叫 Dreambooth(全量微调)。它的代价极其高昂:
- 每次训练都要极其昂贵的显卡算力。
- 每次训练完,你都会得到一个全新、独立、体积高达好几个 GB 的大底模。如果想要 10 个人物,你的硬盘可能直接爆炸。
2. LoRA 的天才设计:冻结与外挂
LoRA (Low-Rank Adaptation) 的提出,极其优雅地解决了这个问题。它的核心数学思想是:做增量,不动存量。
当你在训练一个 LoRA 时:
- 冻结大脑: 它会把 UNet 里面原本那几十亿个参数全部“上锁(冻结)”,在训练过程中绝对不改变它们。
- 旁路注入: 它在 UNet 原本的神经通路旁边,悄悄架设了一条极其细小的“旁路(Bypass)”。
- 低秩矩阵(Low-Rank): 这个旁路不是一个庞大的网络,而是由两个极其小巧的数学矩阵(矩阵 A 和矩阵 B)相乘组成的。
当你生成图像,加载 LoRA 时,AI 引擎在底层做的数学运算极其简单: $$\text{最终发力的权重} = \text{UNet 原本的权重} + \text{LoRA 设定的强度} \times (A \times B)$$
这就是为什么 LoRA 文件只有几十兆(MB)的原因! 它里面根本没有完整的画面结构逻辑,它只记录了**“为了画出刘亦菲,需要在 UNet 原本的知识上,做出怎样的偏移量(Delta)”**。
3. LoRA 具体挂在 UNet 的哪里?
UNet 并不是一个均匀的铁板一块,它里面包含了负责识别边缘的卷积层(Conv),和负责听懂文字的交叉注意力层(Cross-Attention)。
- 绝大多数的 LoRA,都是挂载在 UNet 的“交叉注意力层(Cross-Attention)”上的。
- 交叉注意力层是 UNet 内部的“翻译官和画师对接的会议室”。文本提示词(Prompt)就是在这里和图像产生关联的。
- 把 LoRA 挂在这里,就意味着你可以极其高效地通过修改提示词(比如触发词),来激活这部分特定的神经回路。
补充说明:虽然最新的 Flux.1 抛弃了 UNet 换成了 DiT (Diffusion Transformer) 架构,但 LoRA 的这种“冻结主网络,注入低维矩阵”的数学思想依然完全适用。只不过现在它是挂在 DiT 的 Transformer 块上了。
ControlNet
ControlNet 是一种用于控制图像生成的模型,它可以提高模型的性能。ControlNet 通过将模型的权重进行分解,将权重的某些部分进行缩放,并添加一个额外的权重矩阵,从而实现权重的微调。ControlNet 的主要优点是它可以提高模型的性能,并且可以在训练过程中进行微调。ControlNet 的主要缺点是它需要额外的权重矩阵,并且训练速度可能会变慢。
CLIP
CLIP 是一个用于图像和文本的模型,它可以用于图像和文本的匹配。CLIP 的主要优点是它可以用于图像和文本的匹配,并且可以在训练过程中进行微调。CLIP 的主要缺点是它需要额外的权重矩阵,并且训练速度可能会变慢。
为什么同时需要 VAE、LoRA、ControlNet
为了让你彻底弄清楚它们各自的“分工”,我们可以把用 AI 生成一张精美图片的过程,想象成**“拍摄一部好莱坞电影”**。
在只有文字提示词(Prompt)的时代,AI 画图就像是在开盲盒。你对 AI 说“画一个在赛博朋克城市里喝咖啡的女孩”,AI 每次给你的构图、女孩的长相、画面的色调都完全不一样。
为了从“随机开盲盒”走向“工业级精确控制”,我们就必须引入这三位分工明确的核心片场工作人员:
1. 基础大模型 (Checkpoint / Base Model) —— 【总导演】
- 分工: 提供最基础的世界观、常识和作画能力。
- 作用: 它知道什么是“赛博朋克”,什么是“女孩”,什么是“咖啡”。如果没有其他工具辅助,总导演会根据自己的理解,随机给你拍出一个画面。
2. ControlNet —— 【动作指导与置景师】(控制“空间与结构”)
- 分工: 负责规定画面中物体的物理位置、姿态和几何边缘。
- 为什么要用它: 导演(底模)是很发散的。如果你要求女孩“翘着二郎腿、左手拿杯子、右手托腮”,仅靠文字描述,AI 极大概率会画出畸形的手或者完全错乱的姿势。
- 工作方式: 你丢给 ControlNet 一张带有特定姿势的火柴人骨架图(OpenPose),或者一张线稿(Canny)。ControlNet 就会像画了地标线一样,强制总导演必须在这个固定的骨架和轮廓内作画,彻底锁死构图。
3. LoRA —— 【化妆师与服装道具】(控制“特征与风格”)
- 分工: 负责向画面中注入极其特定的身份特征、画风或材质。
- 为什么要用它: 总导演(底模)脑子里只有泛泛的概念。如果你想画的不是“普通女孩”,而是“刘亦菲”,或者你想让整个画面呈现“特定的 90 年代吉卜力水彩画风”,总导演是做不到的,因为它的知识太宽泛了。
- 工作方式: LoRA 就像一个特训包。挂载“刘亦菲 LoRA”,AI 就会把女孩的脸固定成刘亦菲;挂载“水彩 LoRA”,AI 就会把笔触变成水彩。它管的是“看起来像什么”,不管“在哪”或“做什么动作”。
4. VAE (变分自编码器) —— 【后期调色师】(控制“色彩与像素质感”)
- 分工: 负责将 AI 脑海中高维的数学数据,解码并渲染成人类肉眼看到的最终 RGB 色彩图像。
- 为什么要用它: AI 在生成图像时,其实是在一个极度压缩的“潜空间(Latent Space)”里做复杂的数学运算,而不是直接在画布上涂像素。算完之后,必须通过 VAE 翻译出来。如果 VAE 缺失或不匹配,翻译出来的图片就像是蒙了一层灰白色的雾,或者色彩断层。
- 工作方式: 它在工作流的最后一步介入,拉升对比度、还原真实的物理光影、消除画面的灰暗感,输出最终的高清大图。
总结:为什么必须同时出现在工作流中?
如果你接到了一个商业单:“画一张刘亦菲(特定人物),以李小龙经典的飞踢姿势(特定动作),在水彩画风(特定风格)下的高清海报,色彩要通透明亮(特定画质)。”
这时候,文字提示词已经无能为力了,你必须让它们协同工作:
- 用 大底模 奠定整体图像生成的基础。
- 用 ControlNet (OpenPose) 锁死飞踢的动作,保证人体不崩坏。
- 用 LoRA (人物 + 画风) 确保脸是刘亦菲,质感是水彩。
- 用 VAE 在最后一步解码,确保画面色彩不发灰,像素锐利。
这就是为什么高级的 AI 绘画工作流必然是模块化的——因为**结构(ControlNet)、语义特征(LoRA)和像素色彩(VAE)**在数学和工程上属于完全不同的维度,必须解耦控制才能达到工业级的精度。
加载的文件
可以发现 无论是 UNet 还是 LoRA,都是 .safetense 文件
现在不管是下载几十 GB 的大底模,还是几十 MB 的 LoRA,文件后缀几乎清一色都是 .safetensors(安全张量格式)。
在 AI 绘画刚火起来的时候(比如 2022 年),大家下载的模型基本都是 .ckpt (Checkpoint) 或 .pt (PyTorch) 格式。但现在这些老格式几乎被全面淘汰,被 .safetensors 一统天下,主要原因有三个极其硬核的优势:
1. 绝对的安全(防病毒与黑客)—— 最核心的原因
老式的 .ckpt 格式使用的是 Python 的 Pickle 序列化技术。这种技术有一个致命的黑洞级漏洞:它允许在模型文件里嵌入并执行任意 Python 代码。
这意味着,如果黑客在一个 .ckpt 模型里偷偷写了一段恶意代码,当你开开心心地把它放进 ComfyUI 或 WebUI 点击“加载”的那一瞬间,恶意代码就会在你的电脑后台悄悄运行。在过去,确实发生过黑客通过分享虚假的 AI 模型,盗取用户浏览器密码和数字钱包的真实事件。下载来路不明的 .ckpt 简直就和运行不知名的 .exe 病毒一样危险。
.safetensors 顾名思义(Safe = 安全),它在底层设计上彻底阉割了执行代码的能力。 它里面只包含纯粹的数学矩阵数据(权重参数)。无论黑客怎么伪装,你的系统读取它时只把它当成一堆数字,物理层面上杜绝了中病毒的可能。
2. 极速加载(Zero-copy 零拷贝技术)
当你加载一个 23GB 的 Flux 大模型时,如果是老格式,电脑需要先把这 23GB 从硬盘读到系统内存(RAM)里,然后再费力地复制到显卡显存(VRAM)里。这个过程不仅极其缓慢,而且会导致内存占用瞬间翻倍(直接撑爆 32G 内存)。
.safetensors 支持一种极其高级的底层技术叫 Zero-copy(零拷贝) 和 内存映射(Memory Mapping)。它可以让显卡绕过繁琐的中间步骤,直接从硬盘快速读取数据映射到显存里。
结果就是:模型加载速度获得了史诗级的提升,且加载时内存占用大幅降低。
3. 懒加载(Lazy Loading)
以前加载一个模型,必须把整个几 GB 或几十 GB 的文件全部吞进去才能用。
.safetensors 的文件头设计非常清晰,类似于一本自带目录的字典。系统可以做到按需读取——如果只用到了模型的某几个特定模块,它就只从硬盘里抽那几页的数据,不需要全盘加载。这在运行复杂的高级工作流时,极大地节省了系统开销。
总结
.safetensors 是由 Hugging Face(AI 界的 GitHub)主导推出的新一代模型存储标准。因为它绝对安全、加载极快、又不会撑爆内存,所以一经推出,就迅速统一了整个开源 AI 界的存储格式标准。现在如果你在网上看到老旧的 .ckpt 模型,最好直接无视,只下载 .safetensors 版本。
采样
如果你把 AI 绘画(扩散模型)理解为**“从一块巨大的大理石中雕刻出一座绝美的雕像”**,那么:
- 提示词 (Prompt) 是你给雕刻家的设计图。
- 底模 (UNet/DiT) 是雕刻家的脑子和双手。
- 采样算法 (Sampler) 就是雕刻家手里的凿子和雕刻手法。
- K 采样器 (KSampler) 则是 ComfyUI 里用来控制这把凿子的工作台。
下面我们把这两个概念掰开揉碎了讲。
1. 采样算法 (Sampler) —— 雕刻的手法
AI 作画的本质叫**“扩散与去噪”**。它一开始面对的是一张完全随机的“电视机雪花屏”(纯噪声),然后它要在几步到几十步之内,把这些雪花点一点点擦掉,最终露出下面隐藏的精美图像。
这个“一点点擦掉”的具体数学计算过程,就叫采样算法。
不同的采样算法,就像不同流派的雕刻手法,决定了出图的速度、细节和质感。目前最主流的流派有这几种:
- Euler (欧拉):【直男画师】 最基础、最经典的算法。它看准了目标,直接一条直线走到底。去噪过程非常平滑,一般 20 步就能出几张结构完整的好图。适合用来做测试。
- Euler a (欧拉祖先) / 带有 "a" 的算法:【灵魂画手】 这里的 "a" 代表 Ancestral(祖先)。它的特点是:每擦掉一点噪声,它又会往画面里偷偷加一点新的随机噪声进去。 这导致它永远无法真正“收敛”。你让它画 20 步和画 30 步,可能出来的图完全变了样。它极具创造力和随机性,出来的画面往往比较柔和、有艺术感。
- DPM++ 系列 (如 DPM++ 2M Karras):【强迫症细节控】 目前最受工业界欢迎的先进算法。它的数学逻辑极其复杂,会在每一步反复比对和修正。它的特点是:对细节的刻画极其变态(比如皮肤纹理、布料质感),而且收敛得很快(通常 20-30 步就能达到极高质量)。
2. K 采样器 (KSampler) —— 核心控制台
在 ComfyUI 里,KSampler(K 采样器)是最核心的节点。你所有的连线,最后都要汇聚到这里才能生成图片。
为什么前面要加个 "K"?
这是为了向一位名叫 Katherine Crowson 的天才女程序员致敬。是她将极其高深的常微分方程(ODE)求解器引入了扩散模型,写出了著名的 k-diffusion 代码库,让 AI 画图的速度和质量得到了质的飞跃。现在市面上几乎所有的 AI 画图软件,底层用的都是她优化的算法。
在 KSampler 这个节点面板上,有几个决定生死的参数(也就是你指挥雕刻家的方式):
- Steps (迭代步数): 你允许雕刻家凿几下。步数太少(<10),图是糊的噪点;步数适中(20-30),图最完美;步数太多(>50),不仅浪费显卡算力,画面甚至可能因为过度锐化而崩坏。
- CFG Scale (提示词引导系数): 你要求雕刻家有多“听话”。
- 设置太低(1-3):AI 放飞自我,根本不管你的提示词,画面颜色通常发灰。
- 设置适中(5-8):最平衡,既听你的话,又有合理的艺术发挥。
- 设置太高(>15):AI 为了死板地凑齐你写的所有词,画面会严重过曝、出现色块崩坏(俗称“烧图”)。
- Denoise (重绘幅度): 这在“图生图”时最重要。1.0 表示 100% 重画(原图彻底没用);0.5 表示保留一半原图轮廓,AI 只改细节。
- Scheduler (调度器): 决定了雕刻家每一次下锤的力度。比如著名的 Karras 调度器,它的策略是“一开始大刀阔斧地砍(大步长),快完工时用小挫刀慢慢修细节(小步长)”,极大地提升了出图效率。
总结一句: 采样算法(Euler, DPM++ 等) 是 AI 去除噪声的数学公式;而 KSampler 则是你在软件里调配这些公式的终极指挥台。