生成对抗网络 GAN
GAN的基本思想
GAN全称对抗生成网络,顾名思义是生成模型的一种,而他的训练则是处于一种对抗博弈状态中的。下面举例来解释一下GAN的基本思想。
假如你是一名篮球运动员,你想在下次比赛中得到上场机会。 于是在每一次训练赛之后你跟教练进行沟通:
你:教练,我想打球 教练:(评估你的训练赛表现之后)... 算了吧 (你通过跟其他人比较,发现自己的运球很差,于是你苦练了一段时间)
你:教练,我想打球 教练:... 嗯 还不行 (你发现大家投篮都很准,于是你苦练了一段时间的投篮)
你:教练,我想打球 教练: ... 嗯 还有所欠缺 (你发现你的身体不够壮,被人一碰就倒,于是你去泡健身房)
......
通过这样不断的努力和被拒绝,你最终在某一次训练赛之后得到教练的赞赏,获得了上场的机会。 值得一提的是在这个过程中,所有的候选球员都在不断地进步和提升。因而教练也要不断地通过对比场上球员和候补球员来学习分辨哪些球员是真正可以上场的,并且要“观察”得比球员更频繁。随着大家的成长教练也会变越来越严格。
GAN浅析
GAN的基本结构
GAN的主要结构包括一个生成器G(Generator)和一个判别器D(Discriminator)。
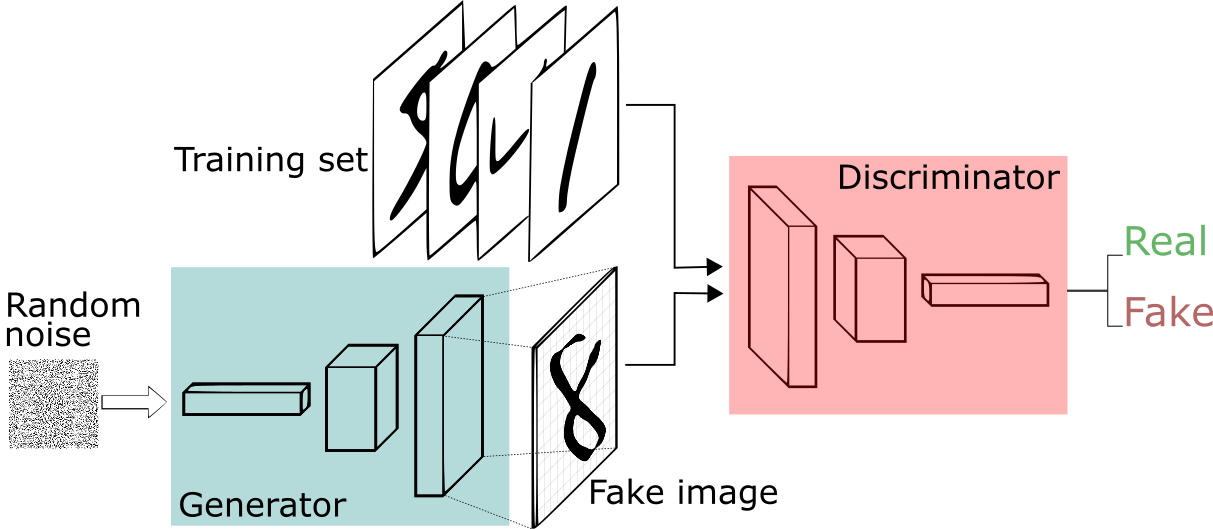
我们现在拥有大量的手写数字的数据集,我们希望通过GAN生成一些能够以假乱真的手写字图片。主要由如下两个部分组成:
- 定义一个模型来作为生成器(图三中蓝色部分Generator),能够输入一个向量,输出手写数字大小的像素图像。
- 定义一个分类器来作为判别器(图三中红色部分Discriminator)用来判别图片是真的还是假的(或者说是来自数据集中的还是生成器中生成的),输入为手写图片,输出为判别图片的标签。
GAN的训练方式
前面已经定义了一个生成器(Generator)来生成手写数字,一个判别器(Discrimnator)来判别手写数字是否是真实的,和一些真实的手写数字数据集。那么我们怎样来进行训练呢?
关于生成器
对于生成器,输入需要一个 $n$ 维度向量,输出为图片像素大小的图片。因而首先我们需要得到输入的向量。
这里的生成器可以是任意可以输出图片的模型,比如最简单的全连接神经网络,又或者是反卷积网络等。这里大家明白就好。
这里输入的向量我们将其视为携带输出的某些信息,比如说手写数字为数字几,手写的潦草程度等等。由于这里我们对于输出数字的具体信息不做要求,只要求其能够最大程度与真实手写数字相似(能骗过判别器)即可。所以我们使用随机生成的向量来作为输入即可,这里面的随机输入最好是满足常见分布比如均值分布,高斯分布等。
假如我们后面需要获得具体的输出数字等信息的时候,我们可以对输入向量产生的输出进行分析,获取到哪些维度是用于控制数字编号等信息的即可以得到具体的输出。而在训练之前往往不会去规定它。
关于判别器
对于判别器不用多说,往往是常见的判别器,输入为图片,输出为图片的真伪标签。
同理,判别器与生成器一样,可以是任意的判别器模型,比如全连接网络,或者是包含卷积的网络等等。
如何训练
基本流程如下:
- 初始化判别器D的参数 $\theta_D$ 和生成器G的参数 $\theta_G$
- 从真实样本中采样 $m$ 个样本 ${x_i}{i=1}^m$,从先验分布噪声中采样 $m$ 个噪声样本 ${z_i}{i=1}^m$ 并通过生成器获取生成样本 ${g_i}_{i=1}^m$。固定生成器G,训练判别器D尽可能好地准确判别真实样本和生成样本,尽可能大地区分正确样本和生成的样本。
- 循环 $k$ 次更新判别器之后,使用较小的学习率来更新一次生成器的参数,训练生成器使其尽可能能够减小生成样本与真实样本之间的差距,也相当于尽量使得判别器判别错误。
- 多次更新迭代之后,最终理想情况是使得判别器判别不出样本来自于生成器的输出还是真实的输出。亦即最终样本判别概率均为 0.5。
之所以要训练k次判别器,再训练生成器,是因为要先拥有一个好的判别器,使得能够教好地区分出真实样本和生成样本之后,才好更为准确地对生成器进行更新。更直观的理解可以参考下图:
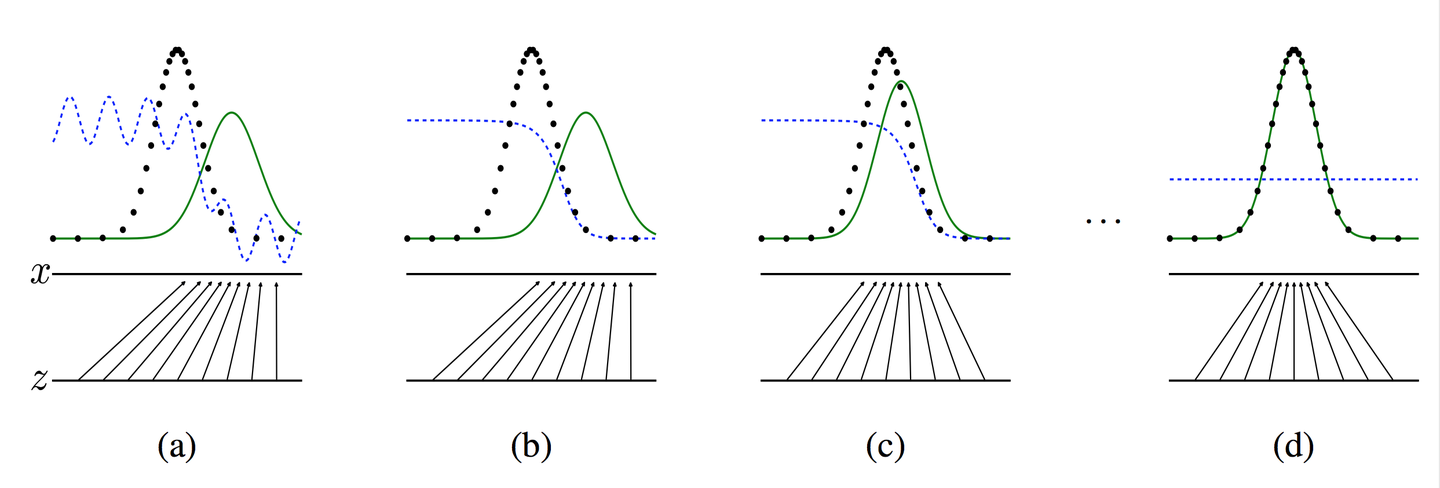
注:图中的黑色虚线表示真实的样本的分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。 表示噪声, 到 表示通过生成器之后的分布的映射情况。
我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的。
可以看到在(a)状态处于最初始的状态的时候,生成器生成的分布和真实分布区别较大,并且判别器判别出样本的概率不是很稳定,因此会先训练判别器来更好地分辨样本。 通过多次训练判别器来达到(b)样本状态,此时判别样本区分得非常显著和良好。然后再对生成器进行训练。 训练生成器之后达到(c)样本状态,此时生成器分布相比之前,逼近了真实样本分布。 经过多次反复训练迭代之后,最终希望能够达到(d)状态,生成样本分布拟合于真实样本分布,并且判别器分辨不出样本是生成的还是真实的(判别概率均为0.5)。也就是说我们这个时候就可以生成出非常真实的样本啦,目的达到。